题目:Learning Deconvolution Network for Semantic Segmentation
作者:Hyeonwoo Noh, Seunghoon Hong, Bohyung Han
年份:2015
会议:ICCV
说面:
Segmantic Segmentation(语义分割)
简单来说就是对图像的每个像素都做分类。输入左边的图片会得到右边分割后后图片。

2.解决的问题
之前使用FCN(注:FCN是2015年发表的论文第一次将卷积神经网络用于语义分割,实现了端到端的语义分割图片的生成)由于要求输入的图片是固定的大小就会存在如下的几个问题(1)如果物体过大话,产生的标签不一致(2)一些小物体的大小会丢失。为此该论文在FCN的基础上进行改进,可以输入任意大小的图片,然后产生相应大小的图片语义分割图片,从而解决以上的问题。
3.研究点
如何将卷积神经网络用于图像语义分割;由于卷积层中的池化操作会使原来图片的大小变小,如何通过反卷积还原原来图片的大小;
4.研究假设
无
5.关键算法
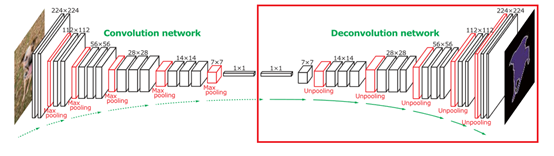
由于是对图像进行处理,论文采用2014年ImageNet的冠军VGG进行前一部分卷积神经网络的构造。后一部分由红色矩形框圈出来的部分进行反卷积还原原来图片的大小,从而进行语义分割的训练与预测。
VGG网络中由于在卷积层使用池化操作(Max Pooling),图片的大小逐渐减少,论文在反卷积层使用UnPooling操作还原原来图片的大小。
UnPooling的操作如下

首先输入的大小为4*4,通过Max Pooling操作后得到2*2(每个矩形框取最大的数)。在Max UnPooling中输入的大小为2*2,通过UnPooling操作,还原为原来的4*4,它会记住原来取最大值的位置,在UnPooling中input的值填充到原来最大值的位置,其他位置填充为0。每一层的卷积后面都有对应的反卷积层。
UnConvolution操作如下:
为了简单说明这里以一维的例子作为说明

输入为{a,b},反卷积过滤器为{x,y,z},stride为1,在输出的时候会将重复的部分相加,因此得到UnConvolution的结果{ax,ay,az+bx,by,bz}
图片通过卷积层以及反卷积层后得到原来图片的大小,这样就可以将标注好的语义分割图片用于训练。
6.数据
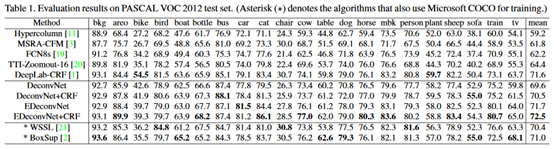
7.优点
可以实现任意大小的图片输入用于语义分割
8.不足之处